
2019 MCG-FNeWS 比赛多模态赛道冠军方案
任务描述
随着多媒体技术的发展,新闻当中通常都包含着文本与图片等多模态信息,不同模态之间既存在着增强关系,同时也包含着互补信息。如何充分利用多模态信息进行虚假新闻检测仍是一项具有挑战的工作,为此,我们设立虚假新闻多模态检测子任务以促进该领域研究。具体任务为:给定一条新闻的多模态内容,包括文本、配图、用户特征等,要求参赛者判断该新闻属于虚假新闻还是真实新闻。
数据集描述
虚假新闻多模态检测任务中,包含文本和图片两种模态的数据。其中文本模态数据字段名和虚假文本检测任务中的字段名解释相同,图片模态和虚假新闻图片检测任务中的解释相同。此外,文本模态还包括“piclist”字段,表示该文本对应的图片,如果没有,则该字段为空,如果有多张,则使用”\t”进行分隔。训练集共有 38,471 条文本以及 34,096 张对应的图片,其中真实新闻共有 19,186 条,对应的图片 20,461 张,虚假新闻 19,285 条,对应的图片 13,635 张。初赛测试集共有 4,000 条文本及 3,855 条对应的图片,复赛测试集共有 3,902 条文本及 3,986 张对应的图片。测试集中真假新闻比例与训练集基本一致。
数据字段:
id:新闻 id,每条文本中 id 均不相同,唯一表征一条新闻;
category: 取值为{财经商业,社会生活,文体娱乐, 科技,医药健康,教育考试,政治,军事},表示新闻所属的类别;
content: 新闻的文本内容;
user info: 新闻的发布者的信息。包含以下字段:gender:发布者性别;followCount: 发布者关注的用户数;fansCount:发布者的粉丝数;location:发布者所在地;description:发布者的个人描述;weiboCount:发布者发布的所有微博数;
label:取值为{0,1},0 表示真实新闻,1 表示虚假新闻。
主办方提供的参考文献清单
• Jin Z, Cao J, Zhang Y, et al. News verification by exploiting conflicting social viewpoints in microblogs. AAAI 2016.
• Jin, Z., Cao, J., Zhang, Y., Zhou, J., & Tian, Q. Novel visual and statistical image features for microblogs news verification. TMM, 19(3).
• Jin, Z., Cao, J., Guo, H., Zhang, Y., & Luo, J. Multimodal fusion with recurrent neural networks for rumor detection on microblogs. MM 2017.
• Guo H, Cao J, Zhang Y, et al. Rumor detection with hierarchical social attention network. CIKM 2018.
• Qi P, Cao J, Yang T, et al. Exploiting Multi-domain Visual Information for Fake News Detection. ICDM 2019.
• Guo C, Cao J, Zhang X, et al. Exploiting Emotions for Fake News Detection on Social Media. arXiv:1903.01728.
多模态赛道 第一名:基于 Gdbts-DenseNet-Bert 联合抽取特征的识别模型
该模型考虑了三类特征,一个方面是图像特征,训练数据中含有图片的样本占了 80% 以上,第二个方面就是文本特征,第三个方面是新闻的发布或者转发者的用户信息特征,比如粉丝数目,关注数,用户简介等用户画像特征。在这里我们使用了 GDBT-based 的模型(梯度增强决策树),针对图像特征,我们使用 densenet121 预训练模型的最后一个全连接层的输出作为图像的语义特征。针对 text 文本字段我们使用了 tfidf 提取 N-gram 特征。最后我们把图像的语义特征,N-gram 和 bert 提取的文本特征,用户画像特征拼接到一起输入 GDBT-based 模型,训练了一个虚假分类的虚假新闻判断模型。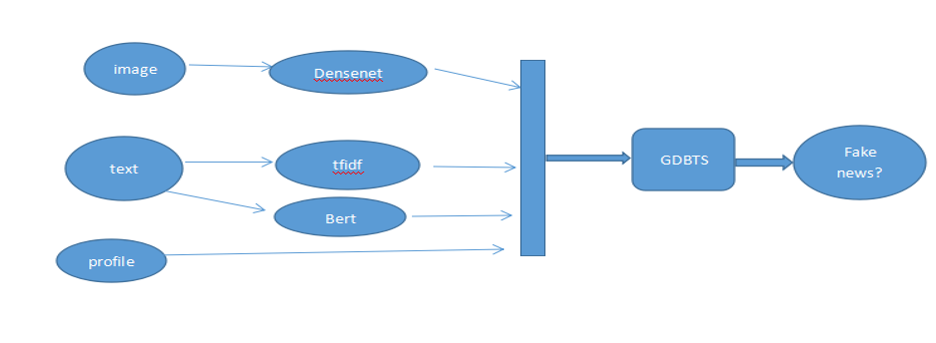
作者对比了 EANN,该论文用到了对抗学习的思想,本质上是多任务联合学习,但是由于比赛的训练样本标签只给出了是否为虚假新闻的字段,并没有标注出改新闻表示的事件。所以针对这里面的比赛数据无法使用论文中的模型框架。我们参试使用了改模型的特征提取层的神经网络模型,后面直接链接 sigmoid 层,训练了一个分类模型,实际测试效果,出现了过拟合现象,线上效果并不是很好。
多模态赛道 第二名:基于 Bert 的多模态真假新闻识别
BERT
Bert 是谷歌 2018 年发布的语言模型,它证明了一个非常深的模型可以显著提高 NLP 任务的准确率,而且模型可以通过无需标记的文本数据训练得到,它大幅度提升了各项 NLP 任务的线上结果。BERT 是构建于 Transformer(见图 1)之上的预训练语言模型,它的特点之一就是所有层都联合上下文语境进行预训练。对于新闻的虚假信息检测,其本质可以看成是 NLP 中的一个文本分类任务。在拿到数据后我们首先使用数据中的新闻内容字段利用 Bert 模型快速地构建了一个 baseline,第一次提交就得到了 F1 得分高达 93% 的线上成绩。我们先后又尝试使用 CNN、LSTM 等普通神经网络模型建模并以不同的方式对它们组合,但线上成绩最也高只有 88% 左右的准确率,和预训练的 bert 模型相差了至少 5 个百分点,这更加证明了 bert 模型的优越性能。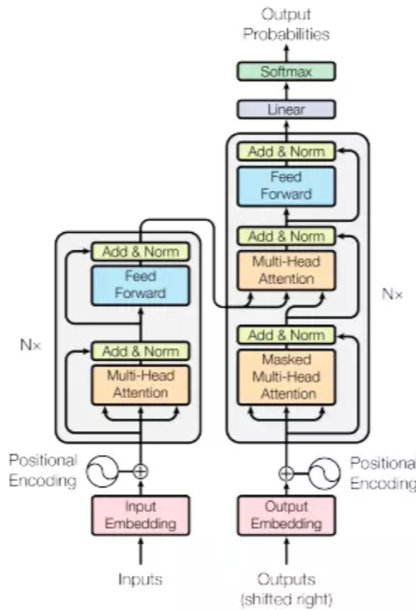
上图是 Transformer 架构图: 左边是编码组件,右边是解码组件,编码组件有六个层,每一层分别由“自注意力层“及”前馈层“组成,解码组件同样有六个层,每一层比编码组件多一个“编码 - 解码注意力层”
我们发现不论是 bert 模型还是其他普通的神经网络模型,线下都能达到 98% 至 99% 的 F1 得分,和线上成绩对比,显然发生了严重的过拟合。经过分析这是由于训练样本中存在着大量的重复样本,导致了在划分训练集和验证集时发生了数据泄露,从而得到很高的线下分数。我们对完全重复的样本进行了去重处理,但发现线上线下分数仍没有明显的变化,然后又利用 fuzzywuzzy 工具包对新闻文本进行字符串模糊匹配,对文本相似度超过 70% 的样本做了剔除,在几个具有高相似的文本中只留下一个,但遗憾的是线下过拟合问题得到了缓解,但线上得分没有提高反而下降了很多,经过分析这可能是由于剔除相似度高的样本后导致训练集和测试集的分布不一致,从而在训练集上训练的模型没能很好的泛化到测试集,也有可能是进行去重处理后训练样本数量减少使得模型性能下降。经过了许多尝试,如果只利用新闻内容字段进行预测,线上分数在 93.x% 就已经达到了瓶颈。
融合新特征
之后我们开始把重点转移到了数据集中发布者的特征信息,如何有效将发布者信息与新闻内容结合来判断新闻的真假性成为了我们新的思考方向。 由于发布者信息的个人描述字段是纯文本,而 bert 模型本身的设计可以接受两段文本的输入,我们很自然地就想到了把发布者的个人描述放到 Bert 输入 Sentence2 中(见图 2),和预期的一样,线上的分中 93.x% 提升到了 95.x%,提升了两个百分点。经过分析,经常发布假新闻的发布者,其个人描述中留下联系方式的概率要远高于普通发布者,而且个人描述中广告信息的概率也远高于普通发布者,而 Bert 很好地根据语义捕捉了这种差异。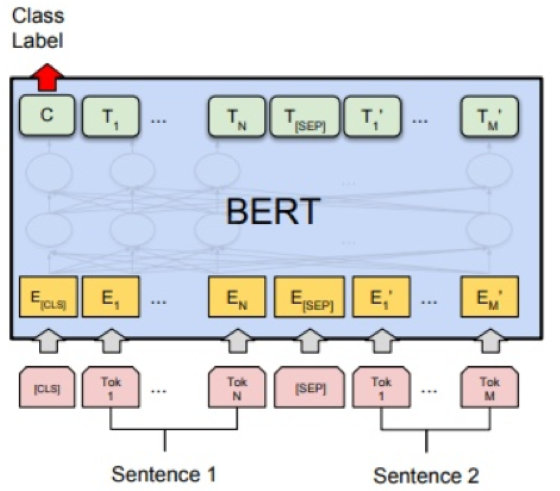
上图是 Bert 用于文本分类基本架构:Sentence 1 和 Sentence2 通过 SEP 分隔符分开,它们文本序列对应的 token 作为输入到 Bert 模型中,利用而外一层输出微调结果。
我们又对发布者的“地点”、“类别”等非数值字段进行了分析,不同地点发布虚假新闻的数量分布有很大的差异,这说明地点字段对真假新闻有一定的区分度。然后又对“类别”字段做了分析,同一篇虚假新闻同时属于多个 “类别”的数量远高于真新闻,而且虚假新闻的内容与其所属类别常常无关,这也符合我们的直觉。直觉上虚假新闻通常是一种带有目的的扩散行为,而且通常是不择手段地扩散,因此虚假新闻都存在着一些共同的不合理特征。因为“地点”字段和“类别”字段都属于文本类型,前面体会到了 Bert 对文本语义提取能力的强大,我们没有使用传统的机器学习常用的特征提取方法对这些字段进行 one-hot 编码或者数值编码操作,而是使用分号符对发布者的“个人描述“、“地点”、“类别”、“性别”等非数值字段进行连接,然后作为 Bert 的第二个文本输入,线上分数从 95.x% 提升到了 96.x%,这也在意料之中。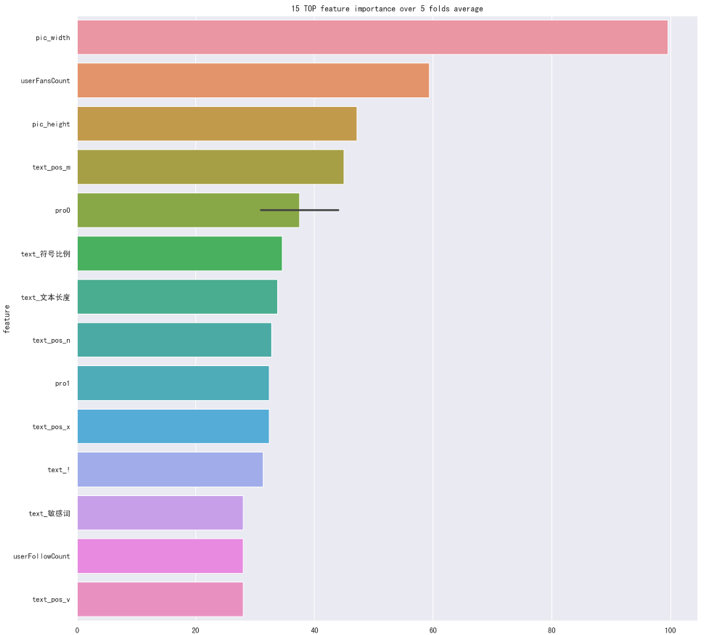
三种方案
目前还剩余发布者关注人数、粉丝数量、发布的文章数量三个数值类字段以及新闻中图片的相关信息。由于 Bert 模型是对文本语义的表示学习,直觉上直接把数值字段与其他文本信息相连接是不可行的,因为不同数值字段之间可能存在着一定的数学运算关系,而 Bert 模型是对语义特征的提取,根据字的上下文来表达一个字的含义,而无法捕捉这种数学运算关系。因此我们最初对已有数值特征做了进一步的提取,比如用粉丝数除以关注数就得到了一个粉丝关注比率特征,类似的还有粉丝数除以微博发布数,关注数除以微博发布数。此外,关于图片也做了简单的特征提取,比如图片的长宽,图片的内存占用大小,新闻中是否存在图片,存在多少张图片等。在进行了一些数值特征的提取后,需要考虑如何才能让 Bert 模型捕捉的语义特征和手工提取的统计特征相结合。
有三种方案:
方案一:使用 LightGBM 的树模型对于数值类特征单独训练,然后将 bert 对真假新闻的概率预测结果和 LightGBM 的概率预测结果以一定的比例相加,然后再参考训练集中正负样本的比例,对测试集根据加权得到的概率也以相同的比例预测结果。
方案二:将 Bert 和 LightGBM 对真假新闻的概率预测作为新的特征,然后使用贝叶斯模型对这两类结果特征做第二次预测,这种方式也叫 stacking。
方案三:对数值特征单独使用一个普通的神经网络进行学习,比如三层的全连接层,然后将普通模型对数值特征学习得到的结果与 Bert 学习得到的结果连接,利用三层 Highway 模型将他们充分的交互,然后使用交互结果做预测。 很遗憾三种方案都没有达到预期的效果。
前面提到 Bert 不能很好的捕捉数值之间的运算关系,于是我们尝试将提取的数值类型特征进行分箱操作,使用了等距和等频的分箱方法把数值类型转换成类别类型,然后将分箱结果直接与其它非数值特征通过分号连接作为新的文本输入到 Bert 中,线上效果提升了几个千分点,但仍没突破 97% 的分数。虽然直接将数值特征加入到 Bert 模型中有违直觉,但我们最后依然做了尝试,我们对手工提取的特征计算重要性并根据重要性做了排序(图三),根据重要性由高到低选取前 n 个的特征将其转化为字符串,然后与非数值特征通过分号相连接作为 Bert 中 Sentence2 的输入,意想不到的是线上分数提升到了 97.3%,对于这样的现象如果要做一个解释,那可能是 Bert 根据这些数值的长度间接的捕捉了数值的大小信息。这也说明了深度学习是一门注重实践的学科,结果的好坏不能单凭直觉,而是要通过实验来检验。
展望
复赛的时间比较短,还有很多非常值得尝试的想法没来得及实践。由于 Bert 能处理的最大文本长度只有 512 个字,而新闻内容加上发布者的特征信息已经远远超过了 512 个字符,在处理超过 512 个字长度的文本时,我们使用了首尾截断的方法,即分别使用文本的头 256 和尾 256 个字符来做预测,而其余的文本内容直接丢弃,这也必然导致很多有用信息的丢失。对于 Bert 的长度处理缺陷导致的信息丢失可以通过以下两种方案得到改善。
方案一:对每个长文本按句切分或者等长切分,得到多个短文本,然后使用 Bert+LSTM 进行分层处理,最后利用 Attention 机制为每个句子计算度量它们重要性的权重。
方案二:计算每个词的 tfidf 权重,每个句子得到一个对应长度为不重复单词数目的稀疏向量,然后利用 SVD、PCA 等方法对其做降维操作,将得到的向量作为文本全局信息的补充,然后与 Bert 提取的语义向量拼接训练进行训练。
此外还可以从增强或者丰富词或字的语义表达上入手,比如利用其它的字 Embedding 方法与 Bert 进行交互训练来丰富文本中每个字的表达。由于 Bert 的处理粒度是字,也可以考虑使用其他方法对词做 Embedding,然后再与 Bert 共同训练。另外 Bert 的模型复杂度实在太高,需要耗费昂贵的时间和设备资源,不妨仿照 ELMO 方法,然后将 ELMO 的损失函数替换成 Bert 的损失函数,定制一个简单的预训练模型来降低模型的复杂度。
多模态赛道 第三名:多模态互联网虚假新闻检测
数据处理
文本预处理
数据处理是初赛阶段的关键,首先我们观察新闻文本部分,除了新闻的正文,文本部分还包含“标题”,“主题”,“qq”,“手机号”,“微信”,“http”,“@”等内容,我们使用正则匹配 + 人工构建过滤规则来进行筛选,对于标题和主题,我们将其提取后,通过固定格式与顺序重新加入到文本的开头部分,对于 http 网址,手机号码,微信,qq 等内容,我们直接将其从新闻文本中去除,并作为当前新闻的其他特征,以待后续处理,对于文本中的 @等内容,我们尝试将其直接去除,并进行分类,结果分类效果反而降低了,因此我们保留了这部分内容,并同时也将其提取作为其他特征。
除真实新闻和虚假新闻数据外,比赛还提供一份辟谣文本库,库中包含多种来源的辟谣文本共 37,877 条,文本库文件中每行展示一条辟谣文本。辟谣库作为辟谣信息,我们考虑其可以用于对训练和测试文本进行辟谣,但由于主办方不保证辟谣文本库与比赛数据集中所述事件的对应性,也未进行去重。
我们通过肉眼观察,可以发现辟谣文本格式较为混乱,其中存在大量重复,并且在部分文本中,同时包含了多条新闻信息。因此我们首先对辟谣文本库进行辟谣,我们使用的是通过部分文本精确匹配来对辟谣库进行去重,具体对于短文本,截取当前文本的中间一定长度的内容,与已去重集合的所有文本对比,如果有找到相同的字符串,则作为重复文本处理,对于长文本,则是取较长的中间一段内容进行类似处理。去重完成后,对于文本中包含多条新闻的通过其包含的标题作为切分,使用正则匹配循环找到所有新闻。另外为了保证辟谣文本的确为辟谣新闻,我们通过关键词‘谣言’,‘辟谣’,‘真相’等词作为过滤词,对于文本的标题中包含这三个词的文本作为辟谣文本,进行进一步的过滤,最终将辟谣文本库的 37877 条文本去重后剩下近 28000 条文本。
新闻事件级别聚类
我们采用 TF-IDF 对事件进行分类,在分词处理过程中加入了停用词表,包括了“我”等常用词和一些语气助词、副词和介词等,并加入标点符号,特殊符号等,将其过滤。另外通过词性方面,保留名词等特征词,将形容词,动词类别过滤。具体详细的过滤词性可以参考我们的代码。分词方面,我们直接通过 jieba 分词,tfidf 模型则使用 gensim 的模型进行训练。最终我们选取对于当前文本 tf-idf 值前 10 的词作为当前文本的特征词向量。获取新闻的特征词向量后,我们通过直接的将文本之间特征向量出现词数 >=6 的新闻作为同类事件处理。
图片预处理
我们对于图片的预处理包括了剔除无效图片以及对图片进行增强。对于数据中存在大量的 gif 格式的图片,我们的做法是随机抽取其中的一帧作为新闻的配图。在剔除了没有办法打开的和格式错误的图片后,我们在训练的时候随机对图片进行了旋转、添加高斯噪声、调整灰度、调整对比度的操作,提升模型的鲁棒性。
预处理模型方法
文本预处理模型
我们采用了 XLNet、Roberta、ERNIE 模型进行文本特征的提取。经过预处理后,我们将文本的话题、标题、特殊结构(网址等)都进行了分离,此处我们采用括号和井号的格式分别表示话题和标题,将二者和文本正文进行拼接,组成规则的文本格式。
在分析新闻结构时,我们发现新闻的文本和博主的个人介绍各自都对新闻的类别有着很强的影响,同时二者间的联系也可以作为判别的有效特征,比如二者在相关的情况下真新闻的可能性就会显著提高。因此我们采用不同段的方式将文本与博主自我介绍进行拼接,同时将博主的地域信息也拼接到了博主的介绍中。
XLNet 是我们尝试过的几个预处理模型中最强力的模型,在只有文本的情况下,XLNet 的准确率可以达到 0.905 左右。我们采用的是 XLNet-mid 中文预训练模型作为 base,在此基础上利用新闻的类别对这一部分单独进行 finetune,最后提取[CLS] 位置的特征作为分类特征进行存储,为后续模型提供 XLNet 文本特征。
Roberta 和 ENIRE 都是 BERT 系列的预训练模型,其在单独的分类效果上并不如 XLNet,但是他们的召回率都很高,在 95% 以上,而且从模型上看,BERT 和 XLNet 具有较大差异,因此我们也把这两个预训练模型提取的特征存储下来,作为文本的自编码特征。BERT 系列模型的输入同样拼接了新闻文本以及博主的个人介绍。
图像预处理模型
我们采用了 Resnext 模型作为预训练模型,我们在图像上的处理较为简单,仅将其作为新闻的一个特征进行整体抽取。我们将图片和其相关的标签进行重新整理,建立一个图片分类任务进行 finetune,并在模型收敛后将分类前的特征作为该图像的特征进行存储。
FakeNewsDection(FND)模型
FND 是我们设计的用来融合各部分特征并提供最终预测的模型,融合的特征包括新闻文本的多个特征、新闻中包含的 n 个图像的特征、新闻博主的个人特征、新闻所属事件的特征。模型的结构图如图所示: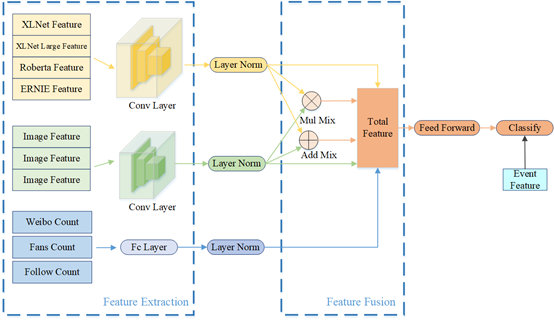
在新闻文本特征中,我们使用了 XLNet_long, XLNet, Roberta 以及 ERNIE 共 4 个模型进行不同角度的特征提取,如上文所示,随后通过卷积的将多个文本特征进行融合。
在新闻图像特征中,我们设置新闻图片的最大阈值为 5,即每条新闻选取 5 张图的 feature,不足则 padding 补齐。与文本特征类似,同样采用卷积的方式将多个图片 feature 进行融合,得到新闻整体的图像特征。
在博主个人特征上比较有价值的是博主微博数、粉丝数和关注数。通过统计观察我们发现真新闻和假新闻在这三个数量的分布上有所不同,但是从个体的角度观察则相互交错而且跨度极大。我们采用“对数”的方式将其压缩到了 1-100 的稠密空间上作为博主的三个特征。
每条新闻除了各部分的独立特征外,不同特征的组合也对新闻的类别判断存在意义,我们将文本和图片特征进行组合。在模型的初步尝试阶段,使用单一属性域特征进行训练,发现不同属性域特征对结果贡献的影响强弱差异大的问题,考虑单一属性域的原始特征嵌入更多的是关注同一属性域里不同特征的差异,忽略不同属性域与之间可能存在的特征组合关系。因此,我们分析了不同特征属性的作用,通过乘积、加和和连接等简单运算,尝试构造了不同属性域之间的交叉特征,如文本特征嵌入和图像特征嵌入的交叉特征,考虑不同属性间的组合关系,从而使得模型实现更好的拟合效果。
除了每一条新闻个体的特征,我们还关注了事件本身的特征。我们按照预处理中的聚类方式将所有新闻按照事件进行聚类,得到 N 个新闻事件,并对新闻事件进行编码,将新闻所属事件与每一条新闻的特征进行融合分类,最终得到每一条新闻的概率值。
我们采用交叉熵损失函数来评估模型对于每条新闻的预测准确性,使用 Adam 作为优化器并采用了 Warm up 以及学习率线性变化的学习策略。
技巧分享
带权重的训练策略
新闻具备很强的类别特征,在训练集中共有 8 个类型的新闻,分别为”财经商业”,”社会生活”,”文体娱乐”,”科技”,”医药健康”,”教育考试”,”政治”,”军事”,在复赛测试集中新增了”灾难事故”类型的新闻。不同类型的新闻有着不同的关注方向以及描述特点,因此模型需要在各个类别上都进行充分训练才能表现良好。由于训练集和测试集在不同类型分布上都存在较大差异,因此我们采用了带权重的训练方式,通过增大“稀有”类别训练权重的方式来增强模型的表现平衡性。
伪标签数据增强
由于复赛测试集和训练集在分布上存在较大差异,例如存在训练集完全没有的“灾难事故”类型的新闻,因此我们使用了伪标签的 Trick 对差异进行弥补,即将之前较好的预测结果作为测试集的“标签”,在开始训练时先训练几轮测试集,然后再正常的在训练集上进行训练,使得模型能更好地在测试集上进行拟合。
Stacking
模型融合是提升模型整体预测能力的一种有效手段,常见的模型融合方法有平均法、Stacking、Blending 等。我们在模型融合中尝试了平均法和 Stacking 两种方法,平均法是以多个模型结果的加权平均值作为最终的计算结果,如此做法能够用多数子模型的正确结果修正少数子模型的错误结果,以达到提升预测能力的作用。但考虑到平均法是每个子模型单独训练的结果,其效果提升相当有限。Stacking 作为模型融合里一种相当有效的方式,以交叉验证的方式重新构造训练集,可以更加关注每个子模型中训练错误的样本,使得最终的简单分类器达到更好的预测效果,在实验中我们最后选择了 5 折交叉验证的方式,以 Logistics 回归作为分类器得到预测结果。
2019 MCG-FNeWS 比赛多模态赛道冠军方案